
Somewhere inside your AI infrastructure, right now, compute is running.
Cooling systems are drawing power. GPUs are processing requests. Billing cycles are accumulating.
And a portion of what you are paying for is not delivering a single token of economically useful work.
You almost certainly don’t know how much. You almost certainly don’t know where. And the tools you are using to monitor your infrastructure were never designed to tell you.
It compounds silently — billing cycle after billing cycle — inside organizations that have never independently measured the gap between what their AI infrastructure is supposed to deliver and what it actually delivers once deployed at scale.
We call it Ghost Capacity™.
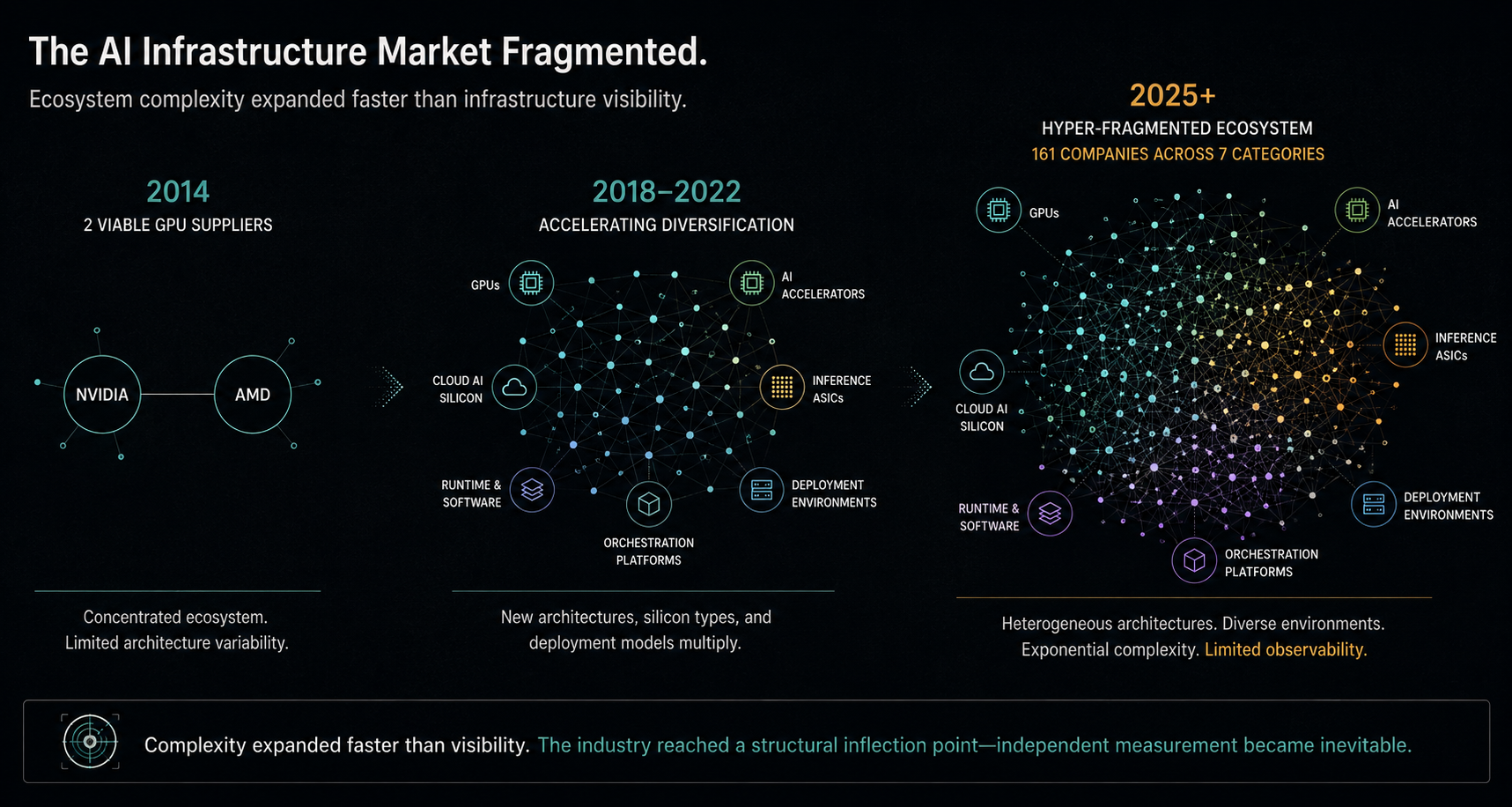
The Market Built A Measurement Gap
Enterprises made purchasing decisions based on benchmark performance. Vendors optimized their benchmark results. Internal teams inherited dashboards that measured what individual layers of the stack were doing — not what the stack was delivering as a whole.
Every layer had visibility into its own slice.
Nobody had visibility into the whole.
The result is a market where every participant measures their own piece — and nobody measures the whole. That structural gap has a name now. And it has a consequence.
Two independent analyst firms arrived at the same conclusion from different directions.
“The AI infrastructure market has arrived at a structural accountability gap. Enterprise AI spend has grown rapidly, but the tools available to measure return on that spend remain fragmented, vendor-biased, or inadequate for production conditions. RunIQ Labs is one of the first companies attempting to address this gap systematically, with a platform aligned to the increasing demand for measurable outcomes, energy-aware infrastructure decisions, and defensible evidence of AI system behavior in production environments.”
“The AI processor market has grown from two viable GPU suppliers in 2014 to 161 companies today — spanning commercially shipping products and active development across seven categories. That fragmentation creates measurement gaps no single vendor is positioned to close. RunIQ is doing the work the market structure requires.”
Concurrent with today’s publication, IDC released independent research coverage of RunIQ Labs. The full research note is available to IDC subscribers at my.idc.com/getdoc.jsp?containerId=lcUS54545326.
Key themes from the IDC research note are reflected throughout this post and in the RunIQ Labs launch press release.
Then We Measured It
Analyst observation identifies a problem. Data proves it exists.
RunIQ Labs instrumented and characterized AI inference deployments across NVIDIA H100, NVIDIA A100, AMD MI300X, and AWS Inferentia2 — under sustained operational conditions that reflect how enterprises actually run AI at scale.
The headline finding:
Sustained runtime throughput diverged from benchmark expectations
by as much as 39%.
Not a rounding error. Not an edge case.
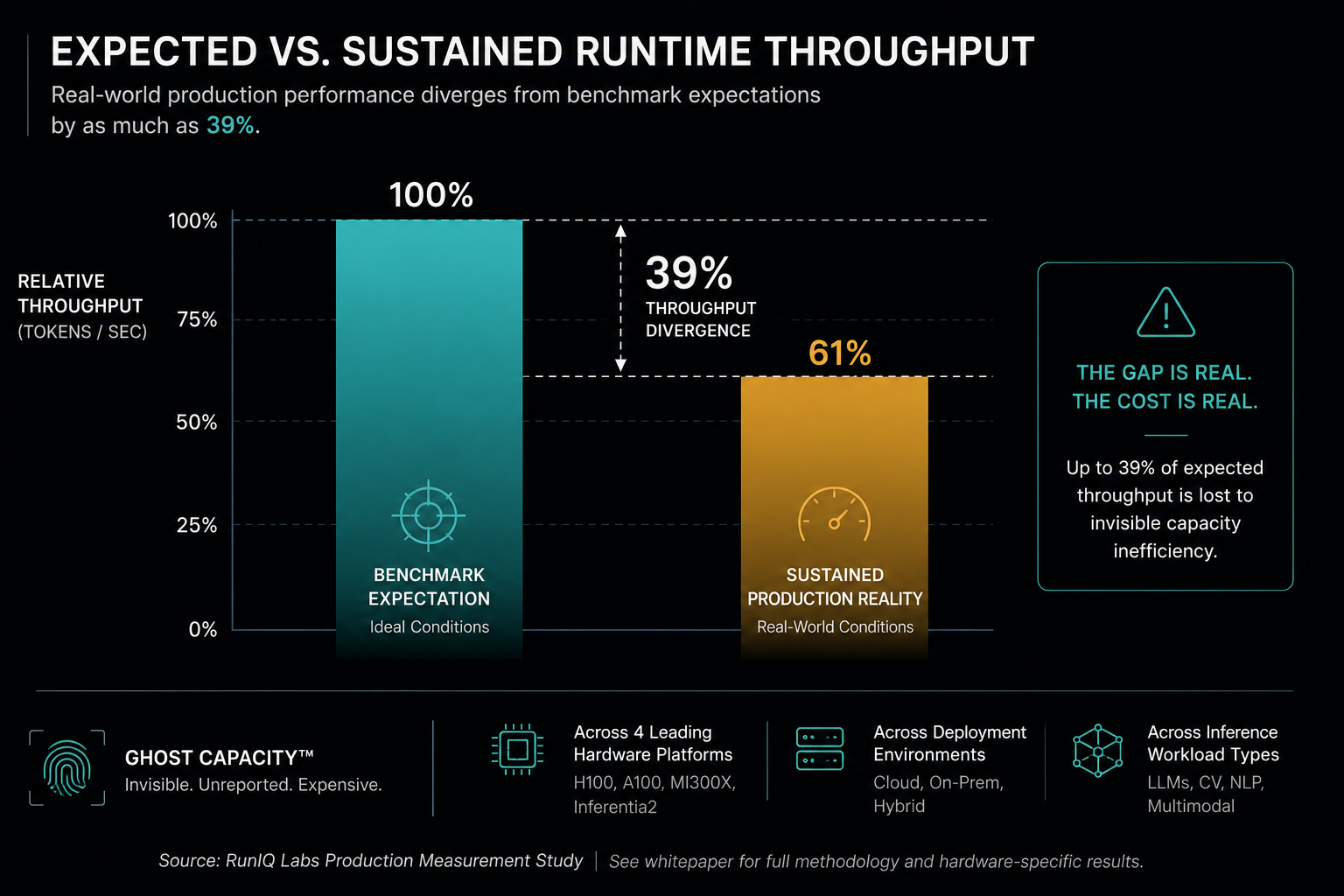
A consistent, documented pattern across hardware architectures, deployment configurations, and inference workload types.
On identical hardware, running identical models at identical precision levels, configuration decisions alone produced throughput variance that translated directly into material cost-per-inference divergence.
Same hardware.
Same model.
Same precision.
Different economic outcome.
You cannot buy your way out of this problem. Better hardware does not close the gap if the gap is a measurement failure, not a hardware failure.
This is not a hardware failure. It is not a model failure.
It is a measurement failure.
Ghost Capacity™ is not a theory. It is a documented and measurable condition — present across enterprise AI deployments that have never been independently characterized at the production level.
The full methodology, deployment-level data, and economic impact analysis are in the whitepaper.
The Accountability Era Has Arrived
As AI infrastructure spending moves from experimentation toward material capital allocation — as CFOs are asked to defend infrastructure decisions in board meetings and regulators begin demanding defensible evidence of AI system behavior — the absence of independent production measurement is transitioning from an operational gap to a fiduciary exposure.
The organizations that establish independent production baselines now will be positioned to defend their infrastructure decisions with evidence rather than assumptions.
The organizations that delay may discover their Ghost Capacity™ only after the economic consequences have materially compounded.

The accountability era for AI infrastructure has begun.
The question is no longer whether independent production measurement becomes necessary.
The question is who moves first.
FIND. RECOVER. DEFEND.